应用场景:
有如下4台主机:
cpy01.dev.xjh.com 第一台日志服务器
cpy02.dev.xjh.com 第二台日志服务器
cpy03.dev.xjh.com 第三台日志服务器
cpy04.dev.xjh.com 日志分析及展示服务器(logstash 和kibana 服务器)
需求: 从cpy01-03 三台服务器导出日志到cpy04中的lostash 过滤数据到elasticsearch,通过elasticsearch 解析聚合,通过kibana 展示出来。
Filebeat 简介:Filebeat 是一款轻量型日志收集工具,可转发汇总日志、文件等内容。
其主要特点为:1. 断点续传。(如遇日志转发过程中网络中断,会在恢复后从断开的点继续转发)
2. 自适应转发速率。(当logstash 处理内容满载时会通知filebeat 转发率减少,当logstash 处于轻松状态,Filebeat则加大转发)
一、 安装Filebeat:
1. 登陆cpy01.dev.xjh.com(需要下载其他版本请点击:https://www.elastic.co/cn/downloads/beats/filebeat )
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.6.1-linux-x86_64.tar.gz -O /opt/filebeat-5.6.1.tar.gz tar xf filebeat-5.6.1.tar.gz -C /usr/local/ mv /usr/local/filebeat-5.6.1-linux-x86_64 /usr/local/filebeat-5.6.1
2. 将/usr/local/filebeat-5.6.1 整个目录拷贝到cpy02.dev.xjh.com和cpy03.dev.xjh.com服务器的/usr/local/目录下
scp -r /usr/local/filebeat-5.6.1 root@cpy02.dev.xjh.com:/usr/local/ scp -r /usr/local/filebeat-5.6.1 root@cpy03.dev.xjh.com:/usr/local/
二、Filebeat配置文件说明:
Filebeat 作为输出工具,可向多种收集工具发送内容,如:logstash(本实验采用直接输出至logstash)、Elasticsearch、kafka、rabbitmq、redis等......
filebeat.yml 简述:
yml 文件以键值对形式存在,均已相同缩进代表相同级别,列表由'-' 表示,配置文件采用折叠式命名规范,如:
filebeat: prospectors: - input_type : log paths: - /var/log/message.log - /usr/local/logs/business.log
意思是:捕获 filebeat.prospectors.0.input+type: log.0./var/log/message.log
和filebeat.prospectors.0.input+type: log.1./usr/local/logs/business.log 两个日志文件
一般折叠式写成:
filebeat.prospectors: - input_type : log paths: ["/var/log/message.log","/usr/local/logs/business.log"] filebeat.prospectors: #filebeat 命名规范,表示捕获文件开始 - input_type : log #表示捕获数据类型为log paths: ["/var/log/message.log","/usr/local/logs/business.log"] #表示日志文件路径
三、配置Filebeat
1. 配置输出至logstash
#==== Filebeat prospectors ======= #==== 定义捕获的日志文件 ======= filebeat.prospectors: - input_type: log paths: ["/usr/local/apache-tomcat-7.0.57/logs/*"] - input_type: stdin #=== Filebeat Global ========= #=== Filebeat 全局配置 ======= filebeat.config_dir:/usr/local/filebeat-5.6.1 #定义filebeat 配置文件目录路径 #==== Filebeat Config prospectors===== #==== 配置重新加载配置文件 ===== filebeat.config.prospectors: path : configs/filebeat.yml reload.enabled : true reload.period : 10s #----------- Logstash Output ------------ #----------- 配置输出到logstash --------- output.logstash: hosts: ["cpy04.dev.xjh.com:5044"] #该列表如果为多个,则采用负载均衡模式发送到列表中的logstash服务器
2. 配置输出至 kafka
#--------- Kafka output ---------- output.kafka: hosts: ["kafka01.dev.xjh.com:9092"] topic: "topicname" partition.round_robin: reachable_only: false required_acks: 1 compression: gzip max_message_bytes: 1000000
3. 配置输出至 elasticsearch
#------- Elasticsearch output -------- output.elasticsearch: hosts:["http://elastic.dev.xjh.com:9200"] username: "elasticsearch-username" password: "elasticsearch-password" template.enabled:true template.path:"filebeat.template.json" template.overwrite:false index:"index-name" ssl.certificate_authorities:["/etc/pki/root/ca.pem"] ssl.certificate:"/etc/pki/client/cert.pem" ssl.key:"/etc/pki/client/cert.key"
4. 配置输出至 redis
#------- Elasticsearch output ---------- output.redis: hosts: ["redis.dev.xjh.com"] password: "redis-password" key: "filebeatkeysname" db: 0 timeout: 10
5. 配置输出至 console
#------- Console output ------- output.console: pretty: true
四、检测配置文件是否有效(如无效,大多为缩进引起):
sudo /usr/local/filebeat-5.6.1/filebeat -configtest /usr/local/filebeat-5.6.1/filebeat.yml
五、 启动Filebeat服务:
sudo /usr/local/filebeat-5.6.1/filebeat -c /usr/local/filebeat-5.6.1/filebeat.yml 2>&1 &
Logstash 简介:
Logstash 是一个实时数据收集引擎,可收集各类型数据并对其进行分析,过滤和归纳。按照自己条件分析过滤出符合数据导入到可视化界面。Logstash 建议使用java1.8 有些版本是不支持的,比如java1.9。
一. 下载安装jdk1.8
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载好的安装包上传到cpy04.dev.xjh.com的/usr/local/ 目录下并三执行如下操作:
#解压文件
tar xf /usr/local/jdk1.8.0_111.tar.gz -C /usr/local mv /usr/local/jdk1.8.0_111 /usr/local/jdk-1.8.0
#添加环境变量
alternatives --install /usr/bin/java java /usr/local/jdk1.8.0/jre/bin/java 3000 alternatives --install /usr/bin/jar jar /usr/local/jdk1.8.0/bin/jar 3000 alternatives --install /usr/bin/javac javac /usr/local/jdk1.8.0/bin/javac 3000 alternatives --install /usr/bin/javaws javaws /usr/local/jdk1.8.0/jre/bin/javaws 3000 alternatives --set java /usr/local/jdk1.8.0/jre/bin/java alternatives --set jar /usr/local/jdk1.8.0/bin/jar alternatives --set javac /usr/local/jdk1.8.0/bin/javac alternatives --set javaws /usr/local/jdk1.8.0/jre/bin/javaws
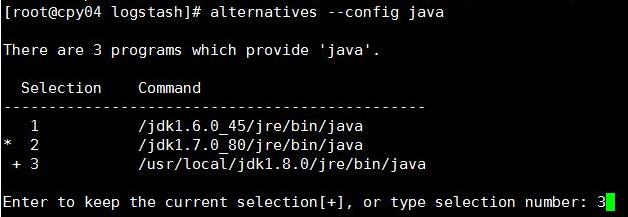
#切换java 版本
alternatives --config java alterconfig.jpg

二. 安装logstash
1. 登陆cpy04.dev.xjh.com(需下载其他版本请点击:https://www.elastic.co/downloads/logstash )
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.6.1.tar.gz -o /opt/logstash-5.6.1.tar.gz tar xf /opt/logstash-5.6.1.tar.gz -C /usr/local mv /usr/local/logstash-5.6.1 /usr/local/logstash
三、配置logstash
1. 编辑 /usr/local/logstash/config/logstash.yml配置文件修改如下内容:
node.name: cpy04.dev.xjh.com #设置节点名称,一般写主机名 path.data: /usr/local/logstash/plugin-data #创建logstash 和插件使用的持久化目录 config.reload.automatic: true #开启配置文件自动加载 config.reload.interval: 10 #定义配置文件重载时间周期 http.host: "cpy04.dev.xjh.com" #定义访问主机名,一般为域名或IP
2. 新建持久化目录:
mkdir -p /usr/local/logstash/plugin-data
3. 配置logstash 从Filebeat 输入、过滤、输出至elasticsearch(logstash 有非常多插件,详见官网,此处不列举)
3.1 安装logstash-input-jdbc 和logstash-input-beats-master 插件
/usr/local/logstash/bin/logstash-plugin install logstash-input-jdbc wget https://github.com/logstash-plugins/logstash-input-beats/archive/master.zip -O /opt/master.zip unzip -d /usr/local/logstash /opt/master.zip
3.2 配置logstash input 段
vim /usr/local/logstash/from_beat.conf
input {
beats {
port => 5044
}
}
output {
stdout { codec => rubydebug }
}启动logstash 看是否能接收到filebeat 传过来的日志内容,要确保filebeat 在日志节点上启动正常。此时只测试传入是否正常,并未对原始日志进行过滤和筛选
/usr/local/logstash/bin/logstash -f /usr/local/logstash/config/from_beat.conf
启动后如果没有报错需要等待logstash 完成,此时间可能比较长
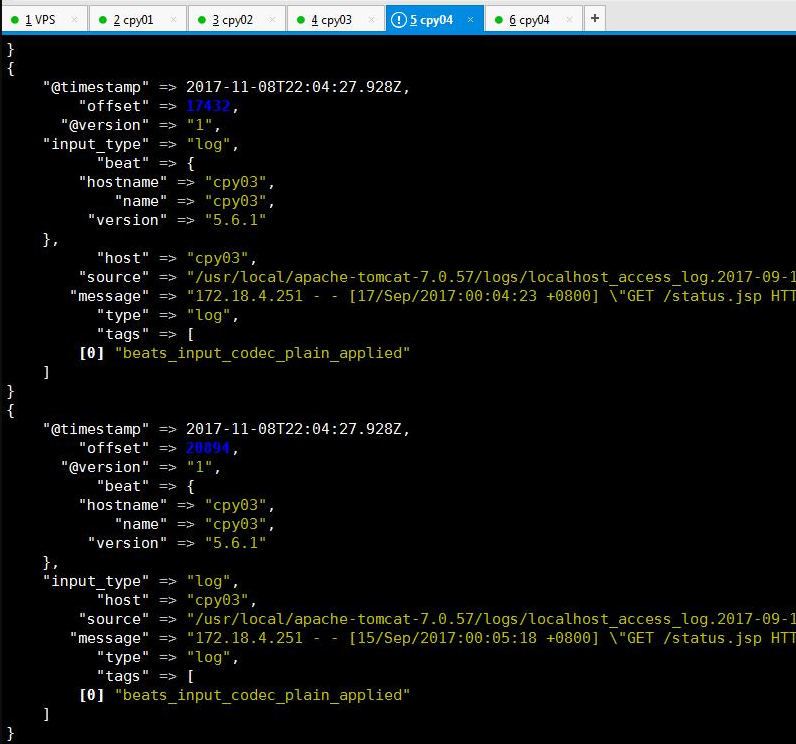
3.3 配置 logstash filter 段,修改/usr/local/logstash/from_beat.conf 为以下内容,配置完成后再次启动logstash,此时如果成功,输出内容应该是自己正则表达式捕获后的字段切分内容。
input {
beats {
port => 5044
}
}
filter {
#过滤access 日志
if ( [source] =~ "localhost\_access\_log" ) {
grok {
match => {
message => [ "%{COMMONAPACHELOG}" ]
}
}
date {
match => [ "request_time", "ISO8601" ]
locale => "cn"
target => "request_time"
}
#过滤tomcat日志
} else if ( [source] =~ "catalina" ) {
#使用正则匹配内容到字段
grok {
match => {
message => [ "(?<webapp_name>\[\w+\])\s+(?<request_time>\d{4}\-\d{2}\-\d{2}\s+\w{2}\:\w{2}\:\w{2}\,\w{3})\s+(?<log_level>\w+)\s+(?<class_package>[^.^\s]+(?:\.[^.\s]+)+)\.(?<class_name>[^\s]+)\s+(?<message_content>.+)" ]
}
}
#解析请求时间
date {
match => [ "request_time", "ISO8601" ]
locale => "cn"
target => "request_time"
}
} else {
drop {}
}
}
output {
stdout { codec => rubydebug }
}
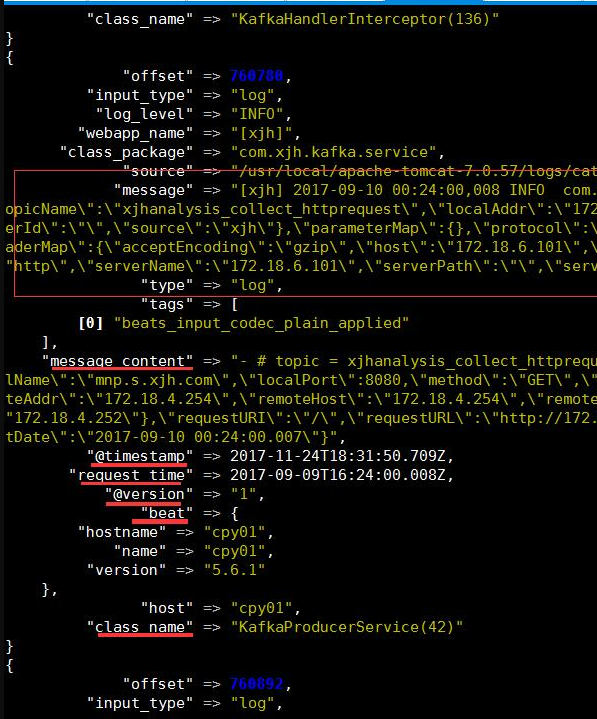
3.4 配置 过滤后内容输出至elasticsearch,修改from_beat.conf 文件为以下内容:
input {
beats {
port => 5044
}
}
filter {
#过滤access 日志
if ( [source] =~ "localhost\_access\_log" ) {
grok {
match => {
message => [ "%{COMMONAPACHELOG}" ]
}
}
date {
match => [ "request_time", "ISO8601" ]
locale => "cn"
target => "request_time"
}
#过滤tomcat日志
} else if ( [source] =~ "catalina" ) {
#匹配内容到字段
grok {
match => {
message => [ "(?<webapp_name>\[\w+\])\s+(?<request_time>\d{4}\-\d{2}\-\d{2}\s+\w{2}\:\w{2}\:\w{2}\,\w{3})\s+(?<log_level>\w+)\s+(?<class_package>[^.^\s]+(?:\.[^.\s]+)+)\.(?<class_name>[^\s]+)\s+(?<message_content>.+)" ]
}
}
#解析请求时间
date {
match => [ "request_time", "ISO8601" ]
locale => "cn"
target => "request_time"
}
} else {
drop {}
}
}
output {
if ( [source] =~ "localhost_access_log" ) {
elasticsearch {
hosts => ["cpy04.dev.xjh.com:9200"]
index => "access_log"
}
} else {
elasticsearch {
hosts => ["cpy04.dev.xjh.com:9200"]
index => "tomcat_log"
}
}
stdout { codec => rubydebug }
}至此,logstash 配置完成。
如果需要做其他过滤或者输出至除elasticsearch 以外插件,
如kafka 详见:https://www.elastic.co/guide/en/logstash/current/index.html
Elasticsearch 是一个分布式搜索引擎,相似产品还有solr-cloud 。Elasticsearch 相对于solr 而言,随着容量的变化,效率会比solr高,特点就是速度快。ES使用者众多,如:StackOverflow、github、维基百科等。
Elasticsearch 至少需要在java1.8 平台,官方建议使用 oracle jdk 1.8.0_131版本。
一、下载安装elasticsearch:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.1.tar.gz -O /opt/elasticsearch-5.6.1.tar.gz tar xf /opt/elasticsearch-5.6.1.tar.gz -C /usr/local vim /usr/local/elasticsearch-5.6.1/config/elasticsearch.yml #编辑elastic配置文件修改成如下内容 cluster.name: logging-cpy #集群名称 node.name: cpy04.dev.xjh.com #es节点ID path.data: /usr/local/elasticsearch-5.6.1/data #es数据存放路径 path.logs: /usr/local/elasticsearch-5.6.1/logs #es 日志存放路径 #禁用内存交换功能,防止性能瓶颈 bootstrap.memory_lock: true network.host: 192.168.12.164 #集群通信节点地址,默认使用回环地址 http.port: 9200 #es 端口 #将同一集群节点全部添加到列表中,会定期扫描急群众服务器的9300和9405端口,做健康检查 discovery.zen.ping.unicast.hosts: ["192.168.12.164"] #防止脑裂,计算公式为"主节点个数/2 + 1" ,例如单点就是1 ,比如3个就是(3/2+1)=2 discovery.zen.minimum_master_nodes: 1
二、 配置系统内存锁定(由于es 配置文件中配置了内存锁定,如果系统不锁定会报:memory locking requested for elasticsearch process but memory is not locked)
vim /etc/security/limits.conf #添加如下内容 * soft memlock unlimited * hard memlock unlimited
三、配置可创建最大文件(解决:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536])
vim /etc/security/limits.conf * soft nofile 65536 * hard nofile 65536
四、配置可创建线程数(解决:max number of threads [1024] for user [elastic] is too low, increase to at least [2048])
vim /etc/security/limits.d/90-nproc.conf #* soft nproc 1024 #注释这行改为2048 * soft nproc 2048 root soft nproc unlimited
五、修改最大虚拟内存大小(解决:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144])
vim /etc/sysctl.conf #添加如下内容 # max virtual memory size vm.max_map_count=633360 保存退出后使用:sysctl -p 命令生效sysctl.conf 配置
六、解决centos6.x 不支持SecComp,ES5.2 后的版本默认使用 bootstrap.system_call_filter 检测,如果不通过则终止ES 进程,所以将该项改为false
vim /usr/local/elasticsearch-5.6.1/config/elasticsearch.yml bootstrap.system_call_filter: false
七、 添加启动elasticsearch 用户(es 默认不能使用root 用户启动)
groupadd elastic useradd elastic -g elastic
八、启动elasticsearch
su - elastic /usr/local/elasticsearch-5.6.1/bin/elasticsearch -d
